AdaBoost This blog post will provide you with a comprehensive overview of Adaboost, exploring the theory behind this probabilistic algorithm and demonstrating its implementation using Python libraries. Dive in to uncover the advantages and disadvantages of neural network, as well as its real-world applications across various domains. With that, enjoy your journey in QDO! What is Adaboost AdaBoost (Adaptive Boosting) is an ensemble learning technique that combines multiple weak classifiers (often decision trees) to create a strong classifier. It works by training the weak classifiers sequentially, giving more weight to misclassified instances at each step so that subsequent classifiers focus more on the harder cases. The final prediction is made by combining the weighted votes of all weak classifiers. AdaBoost is effective at reducing bias and variance, and it’s particularly good for binary classification problems. However, it can be sensitive to noisy data and outliers. Concepts o...
GRADIENT BOOSTED TREES

This blog post will provide you with a comprehensive overview of gradient boosted trees, exploring the theory behind this probabilistic algorithm and demonstrating its implementation using Python libraries. Dive in to uncover the advantages and disadvantages of gradient boosted trees, as well as its real-world applications across various domains. With that, enjoy your journey in QDO!
WHAT IS Gradient Boosted Trees
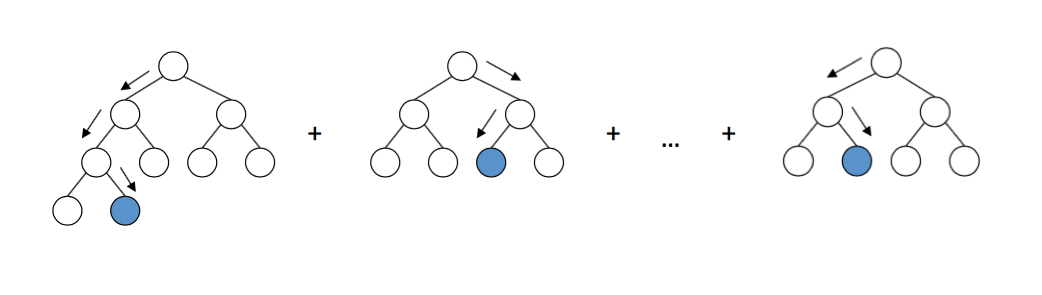
Gradient Boosted Trees (GBT) is a powerful supervised machine learning algorithm primarily used for tasks involving regression and classification. It builds an ensemble model by iteratively training a sequence of decision trees, where each tree attempts to correct the errors of the previous trees. The process starts with an initial model, often a simple one like predicting the mean of the target variable, and then adds trees sequentially.
Concept of gradient boosted trees
Let's say we want to predict the weight of a person using attributes like the height of the individual, their gender and favorite color.

We create the first leaf by calculating the medium of the weight,
Then we proceed to make a decision tree base on the errors we made previously to improve the result


The average weight would be (88+76+56+73+77+57) /6 = 71.2
Lets assume all the individual have the same weight so the predicted weight for all records would be 71.2

After that, we make a decision tree but using the value of the residuals as the leaf. Within the decision tree below, we set the maximum number of leaf to 4.

If more than 1 records end up in the same leaf, we take the average value of these records. The fully updated decision tree is presented as below.

The predicted value for the first record would be

71.2(average weight) + 16.8(the leaf residual) = 88
Which is the same as the actual weight of our first record here

However, by doing so we will end up having a low Bias but probably a very high variance. Hence, we scale the value using Learning Rate which value is between 0 and 1.

Hence, the predicted value = 71.2 + (0.1 * 16.8) = 72.9.
The new residual for the record would be 88 - 72.9 = 15.1
If we compare both the current residual and the one previously, we notice the value had decreased which indicates that we are getting more and more closer to the actual value for every repetition.

The entire process repeats and the value is calculated by adding the predicted value and all scaled residuals.

Implementation of gradient boosted trees in python
Importing libraries
import pandas as pd
from sklearn import datasets
Loading dataset
wine = datasets.load_wine(as_frame=True)
Define dependent and independent variable
X=wine['data']
Y=wine['target']
Splitting dataset into training and testing
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2,random_state=17)
Applying the model
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
gbr=GradientBoostingClassifier()
gbr.fit(X_train,Y_train)
Get prediction result
cross_val_score(gbr, X_train, Y_train, cv=3, n_jobs=-1).mean()
0.9221335697399526
Parameters that you can tune in gradient boosted trees
Learning Rate (eta):
- Controls the contribution of each tree; a lower rate results in slower learning but may enhance generalization.
Number of Estimators (n_estimators):
- Total number of trees to be added to the model; more trees can improve performance but may risk overfitting.
Maximum Depth (max_depth):
- Maximum depth of each tree; deeper trees can capture complex relationships but may lead to overfitting.
Minimum Samples Split (min_samples_split):
- Minimum number of samples required to split an internal node; helps prevent overfitting by ensuring nodes contain sufficient samples.
Minimum Samples Leaf (min_samples_leaf):
- Minimum number of samples required to be at a leaf node; increasing this number can smooth the model and reduce overfitting.
Subsample:
- Fraction of samples used for fitting each tree; introduces randomness and helps prevent overfitting.
Colsample_bytree:
- Fraction of features (columns) to be sampled for each tree; adds randomness to reduce overfitting.
Gamma (min_split_loss):
- Minimum loss reduction required to make a further partition on a leaf node; a larger value leads to a more conservative model.
Regularization Parameters (alpha and lambda):
- Alpha (L1 regularization): Adds a penalty equal to the absolute value of coefficients; helps reduce overfitting.
- Lambda (L2 regularization): Adds a penalty equal to the square of the coefficients; helps control model complexity.
Scale Pos Weight:
- Used in unbalanced datasets to balance the weights of positive and negative classes, focusing more on the minority class.
Boosting Type:
- Defines the type of boosting model to use (e.g., 'gbtree', 'gblinear', 'dart'); affects how trees are constructed.
Early Stopping:
- Technique to stop training when performance on a validation set no longer improves; helps prevent overfitting.
Tree Method:
- Specifies the tree construction algorithm to use (e.g., 'exact', 'approx', 'hist'); affects performance and scalability.
Learning Rate (eta):
- Controls the contribution of each tree; a lower rate results in slower learning but may enhance generalization.
Number of Estimators (n_estimators):
- Total number of trees to be added to the model; more trees can improve performance but may risk overfitting.
Maximum Depth (max_depth):
- Maximum depth of each tree; deeper trees can capture complex relationships but may lead to overfitting.
Minimum Samples Split (min_samples_split):
- Minimum number of samples required to split an internal node; helps prevent overfitting by ensuring nodes contain sufficient samples.
Minimum Samples Leaf (min_samples_leaf):
- Minimum number of samples required to be at a leaf node; increasing this number can smooth the model and reduce overfitting.
Subsample:
- Fraction of samples used for fitting each tree; introduces randomness and helps prevent overfitting.
Colsample_bytree:
- Fraction of features (columns) to be sampled for each tree; adds randomness to reduce overfitting.
Gamma (min_split_loss):
- Minimum loss reduction required to make a further partition on a leaf node; a larger value leads to a more conservative model.
Regularization Parameters (alpha and lambda):
- Alpha (L1 regularization): Adds a penalty equal to the absolute value of coefficients; helps reduce overfitting.
- Lambda (L2 regularization): Adds a penalty equal to the square of the coefficients; helps control model complexity.
Scale Pos Weight:
- Used in unbalanced datasets to balance the weights of positive and negative classes, focusing more on the minority class.
Boosting Type:
- Defines the type of boosting model to use (e.g., 'gbtree', 'gblinear', 'dart'); affects how trees are constructed.
Early Stopping:
- Technique to stop training when performance on a validation set no longer improves; helps prevent overfitting.
Tree Method:
- Specifies the tree construction algorithm to use (e.g., 'exact', 'approx', 'hist'); affects performance and scalability.
Advantages and disadvantages of gradient boosted trees
Advantages
- High Accuracy: Gradient boosting often provides superior predictive performance, as it reduces errors through iterative learning from previous models' mistakes.
- Handles Complex Data Well: It can capture complex, non-linear patterns in the data, making it suitable for diverse applications like finance and healthcare.
- Feature Importance: It naturally provides feature importance scores, helping to identify the most influential features for the predictions.
Disadvantages
- Computationally Intensive: Training gradient boosted trees is time-consuming and requires substantial computational resources, especially with large datasets.
- Sensitive to Overfitting: Gradient boosting can overfit, particularly with noisy data, so it often requires careful parameter tuning.
- Hard to Interpret: The model complexity makes gradient boosted trees less interpretable compared to simpler models, limiting transparency in decision-making.
Comments
Post a Comment